|
Page préc.
Systèmes de fichiers classiques |
Fin de page |
Page suiv.
Quelques autres systèmes de fichiers reconnus par Linux |
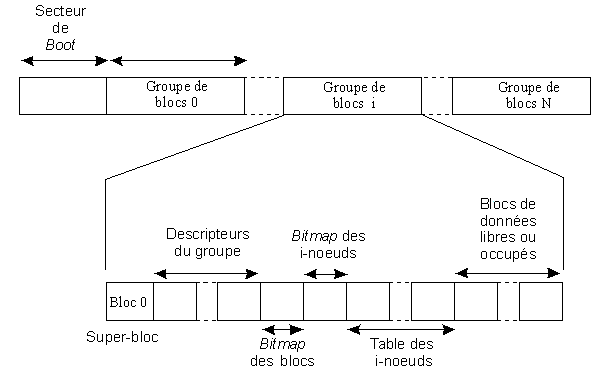
Rappelons que, comme tout F.S [1], ext2 commence par le secteur de boot qui peut contenir le programme de démarrage ou être vide. Puis il est divisé logiquement en petites unités appelées blocs. Un bloc est la plus petite unité qui peut être allouée. Chaque bloc du F.S. peut être allouée ou libre. La taille des blocs est un multiple de la taille d'un secteur, elle peut être de 1024, 2048 ou 4096 octets, elle est fixée à la création du F.S. Les grands blocs accélèrent les temps d'accès (moins d'accès physiques au disque), mais impliquent généralement un taux de remplissage plus faible. Un bloc peut être découpé en fragments destinés à contenir la fin d'un fichier. Ce bloc peut donc contenir les derniers fragments de plusieurs fichiers. La taille des fragments dépend de celle des blocs.
Les blocs sont eux-mêmes organisés en groupes de blocs. Dans un F.S. , chaque groupe de blocs du F.S. ext2 contient une table des i-nuds, (i-node, abréviation de index-node). Un i-noeud contient toutes les informations nécessaires au système pour gérer le fichier correspondant. Le nombre d'i-nuds par groupe de blocs est limité.
Le premier bloc d'un groupe, le bloc 0, est appelé le superbloc. Il continet des informations spéifiques, différentes des autres blocs. Il est décrit plus loin.
Chaque groupe contient (dans une table) la description de tous les groupes de blocs. Seule la table de description des groupes présente dans le groupe 0 est normalement utilisée. Les autres copies qui apparaissent dans les autres groupes ne servent qu'en cas de destruction de la première.
La table de description des blocs de chaque groupe de bloc est une structure de type ext2_group_desc, décrite plus bas. Elle commence dans le bloc 1 (le bloc 0 étant le superbloc, évoqué ci-dessus).
Un des blocs du groupe contient "l'image bitmap des blocs alloués" (block allocation bitmap block) : à chaque bit à 0 correspond au même rang un bloc unallocated dans le groupe, et à chaque bit à 1 correspond un bloc allocated. Un autre bloc du groupe,"l'image bitmap des blocs alloués" (inode allocation bitmap), joue le même rôle pour les i-nuds libres ou alloués. Ces deux blocs sont utilisés lors de la recherche d'un emplacement libre lors de la création d'un nouvel i-nud ou de l'allocation d'un nouveau bloc à un fichier. On reconnaît ici une technique identique à celle qui a été présentée dans le chapitre consacré à la gestion mémoire : "Table de description de la mémoire (mapping)".
Un groupe de blocs est décrit par une structure de type ext2_group_desc ci-dessous :
| struct ext2_group_desc {
__u32 bg_block_bitmap; __u32 bg_inode_bitmap; __u32 bg_inode_table; __u32 bg_free_block_count; __u32 bg_free_inode_count; __u32 bg_used_dirs_count; __u32 bg_pad; __u32 bg_reserved [3]; }; |
dans laquelle les champs ont les significations suivantes :
bg_block_bitmap numéro du bloc qui contient "l'image bitmap des blocs alloués" bg_inode_bitmap numéro du bloc qui contient "l'image bitmap des i-nuds alloués" bg_inode_table numéro du premier bloc qui contient la table des i-nuds bg_free_block_count
bg_free_inode_count
bg_used_dirs_countnombre de blocs et d'i-nuds libres, et nombre de répertoires utilisés dans le groupe de blocs (utilisés comme statistiques pour équilibrer l'occupation des différents groupes de blocs)
| struct ext2_super_block {
__u32 s_inodes_count; __u32 s_blocks_count; __u32 s_r_blocks_count; __u32 s_free_blocks_count; __u32 s_free_inodes_count; __u32 s_first_data_block; __u32 s_log_block_size; __s32 s_log_frag_size; __u32 s_blocks_per_group; __u32 s_frags_per_group; __u32 s_inodes_per_group; __u32 s_mtime; __u32 s_wtime; __u16 s_mnt_count; __s16 s_max_mnt_count; __u16 s_magic; __u16 s_state; __u16 s_errors; __u16 s_pad; __u32 s_lastcheck; __u32 s_checkinterval; __u32 s_creator_os; __u32 s_rev_level; __u16 s_def_resuid; __u32 s_ def_regid; __u32 s_reserved[235]; }; |
dans laquelle les champs ont la signification suivante :
Remarques :
Caractéristiques du F.S s_inodes_count
s_blocks_countnombre total de blocs et d'i-nuds disponibles s_free_blocks_count
s_free_inodes_countnombre de blocs et d'i-nuds libres s_first_data_block s_log_block_size
s_log_frag_sizetaille d'un bloc (en octets : 1024, 2048 ou 4096) ou d'un fragment utilisée lorsque des fragments de blocs de plusieurs fichiers sont réunis dans le même bloc s_blocks_per_group
s_frags_per_group,
s_inodes_per_groupnombre de blocs, de fragments et d'i-nuds par groupe s_mtime, s_wtime date de montage et de dernière écriture Vérifications s_mnt_count
s_max_mnt_countchaque fois que le F.S. est monté en "lecture/écriture", s_mnt_count est incrémenté. Lorsque la valeur s_max_mnt_count est atteinte, un test de vérification (e2fsck) est automatiquement lancé s_lastcheck
s_checkintervalde la même façon, s_lastcheck enregistre la date du dernier test et s_checkinterval indique l'intervalle maximal de temps entre deux validations (0 signifie que cette vérification est désarmée) Traitement d'erreurs s_state lorsqu'un F.S. est monté en "lecture/écriture", le kernel positionne le bit 0 de cette variable à "not clean". Lorsque F.S. est démonté ou remonté en "lecture seule", son état est remis à "clean". Au moment du boot, le testeur de F.S. utilise cette information pour savoir si un F.S. doit être vérifié. Le kernel positionne à 1 le bit 1 de cette variable lorsqu'il détecte une erreur dans le F.S. s_errors détermine quel doit être le comportement du kernel en cas d'erreur : ignorer l'erreur si s_errors = 1, remonter le F.S. en lecture seule si s_errors = 2, "paniquer" si s_errors = 3 Identification s_magic identification du F.S. (0xEF53 pour Linux) s_creator_os code du S.E. qui a créé ce F.S. : 0 pour Linux, 1 pour Hurd et 2 pour Masix s_rev_level numéro de la révision de la version majeure de ext2 : 0.5b pour la révision du 09/08/95 actuellement utilisée Administration s_r_blocks_count nombre de blocs réservés pour l'administrateur (root), l'utilisateur d'identificateur s_def_resuid ou le groupe d'identificateur s_def_regid. Le système refuse d'allouer les s_r_blocks_count derniers blocs libres si l'utilisateur n'appartient pas à cet ensemble Autres s_pad utilisé pour aligner les champs sur 32 bits s_reserved[235] utilisé pour remplir la fin du bloc
| struct ext2_inode {
__u16 i_mode; __u16 i_uid; __u32 i_size; __u32 i_atime; __u32 i_ctime; __u32 i_mtime; __u32 i_dtime; __u16 i_gid; __u16 i_links_count; __u32 i_blocs; __u32 i_flags; struct {__u32 l_i_reserved1; } linux1; __u32 i_block [EXT2_N_BLOCKS];
}; // ext2_inode |
dans laquelle les champs ont la signification suivante :
i_mode permet de définit le type de fichier et les permissions associées. Les quatre digits en octal les plus à droite représentent les bits "options" (voir compléments de cours pour les TPs concernant les fichiers : "Protection des fichiers" : rwx pour le user, le groupe et les autres. Les deux digits en octal les plus à gauche déterminent le type de fichier (voir plus loin).
01 FIFO 02 périphérique caractère 04 répertoire 06 périphérique bloc 10 fichier régulier 12 lien symbolique 14 socket i_uid
i_gidId de l'user et du groupe propriétaires i_size taille du fichier, en octets, lorsqu'il s'agit d'un fichier régulier. A une signification particulière lorsqu'il s'agit d'un autre type de fichier i_atime
i_ctime
i_mtime
i_dtimerespectivement date du dernier accès, de la création, de la dernière modification, exprimés en secondes à partir du 1er janvier 1970 00:00:00 GMT i_links_count nombre de liens physiques (hard links) sur cet i-nud à partir de différents répertoires i_blocs nombre de blocs i_flags ensemble de bits permettant de positionner des options (certaines ne sont pas implémentées mais seulement prévues :
0 secure deletion (effacement sécurisé): lorsque le fichier est effacé, tous les blocs qui le composaient sont remplis de 0. Certaines documentations indiquent que ce sont des valeurs aléatoires qui sont utilisées 1 Undelete : non implémenté 2 Compress file : compression à la volée. Non implémenté 3 synchronous updates (mises à jour synchrones) : toutes les modifications sont immédiatement écrites sur le disque, comme avec l'option O_SYNC de la fonction système open(). 4 immutable file : le fichier ne peut être modifié, effacé, renommé, aucun lien physique ne peut être créé, etc. tant que le bit n'est pas dépositionné. 5 Append only file : des données ne peuvent être ajoutées qu'en fin de fichier 6 le fichier ne peut être dumpé linux1 zone réservée : dépend du S.E. (linux, hurd ou masix) i_block table d'implémentation des blocs du fichier (voir ci-dessous) i_version version du fichier (pour NFS) i_file_acl
i_dir_aclfichier et répertoire ACL (Access Control List). permet un contrôle beaucoup plus sophistiqué que les simples bits de permissions i_faddr adresse du fragment linux2 zone réservée : dépend du S.E. Utilisée pour la gestion des fragments de fichiers regroupés dans certains blocs : contient essentiellement le numéro du fragment et sa taille.
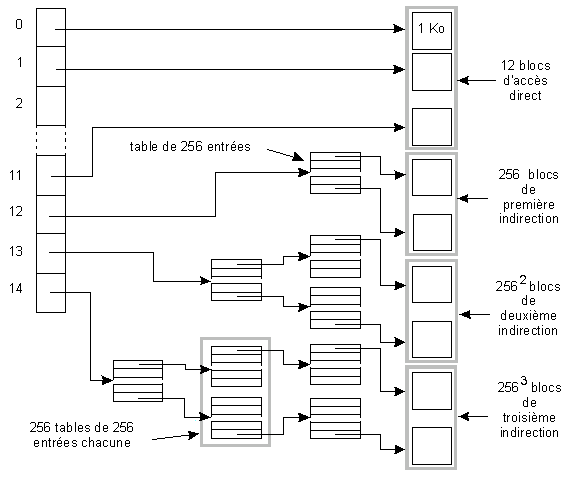
Les entrées 0 à 11 pointent directement sur le bloc de données correspondant. Si un bloc fait 1024 octets, et si l'offset de la donnée est 4219, elle se trouve au déplacement 4219 % 1024 = 123 (% signifie modulo) dans le bloc pointé par i_block [4219/1024 = 4]. L'accès est donc direct pour tous les fichiers de taille inférieure à 12 x 1024 octets (12 Ko).
L'entrée 12 pointe sur un bloc qui contient lui même une table de blocs. Chaque entrée faisant 4 octets (_u32), un bloc peut contenir 256 entrées, ce qui permet d'atteindre des tailles de fichiers de 12 Ko + 256 * 1 Ko = 268 Ko.
L'entrée 13 permet une double indirection : les 256 blocs accessibles par la première indirection sont eux-mêmes des tables de blocs. La taille maximale de tels fichiers est alors de 12 Ko + 256 * 1 Ko + 256 * 256 * 1 Ko = 65804 Ko
L'entrée 14 permet une triple indirection. La taille maximale de tels fichiers est alors de 12 Ko + 256 * 1 Ko + 256 * 256 * 1 Ko + 256 * 256 * 256 * 1 Ko = 16843020 Ko, soit plus de 16 Go. Il suffit d'ajouter un élément dans la table initiale pour permettre des fichiers de l'ordre de 4 To (Tera octets !).
Il apparaît donc que l'accès aux petits fichiers est rapide, et que seuls les gros ou très gros fichiers sont pénalisés par une indirection simple ou multiple.
La figure ci-dessous illustre la structure de cette table.
Remarques :
| 1 | bad block inode : liste des blocs abîmés |
| 2 | root inode : i-nud du répertoire de la racine du F.S. |
| 3 | acl index inode |
| 4 | acl data inode |
| 5 | boot loader inode |
| 6 | undelete directory inode |
| 7-10 | reserved |
| struct ext2_dir_entry {
__u32 inode; __u16 rec_len; __u16 name_len; char name [EXT2_NAME_LEN]; }; // ext2_dir_entry |
dans laquelle les champs ont la signification suivante :
Les répertoires sont donc le seul moyen d'établir une correspondance entre un fichier et son nom. Contrairement à une table habituelle, les entrées d'un répertoire sont de taille variable, afin d'économiser l'espace disque pour les noms de fichiers courts. La taille d'une entrée étant arrondie au multiple de 4 supérieur, les octets de remplissage sont initialisés à 0.
__u32 inode pointeur vers l'i-nud du fichier __u16 rec_len longueur de l'entrée (un nombre d'octets, multiple de 4) __u16 name_len longueur du nom du fichier (<= 255 octets) char name [EXT2_NAME_LEN] nom du fichier
Lors de la suppression d'un élément dans la table, les octets qui le composent sont mis à 0 et ajoutés à la taille de l'élément qui le précède.
Les deux premières entrées d'un répertoire sont toujours '.' et '..' représentant respectivement "ce répertoire" et "le répertoire parent".
Afin d'atténuer ces deux inconvénients, d'une part le SGF (plus précisément VFS) utilise des caches mémoire, d'autre part Ext2fs utilise des liens symboliques rapides [2] : les 15 éléments du tableau i_block occupent 64 octets. Si la taille du nom du fichier est inférieure à 65, le nom est directement stocké dans le vecteur i_block.
[1] au sens "support logique d'une arborescence" ou "partition"
[2] Cette technique a été envisagée pour les fichiers ordinaires (regular files) : stocker directement dans le tableau i_block les octets de données pour les fichiers de moins de 65 octets. J'ignore si cette amélioration a été implémentée dans la version actuelle de Ext2fs (0.5b).
|
Page préc.
Systèmes de fichiers classiques |
Début de page |
Page suiv.
Quelques autres systèmes de fichiers reconnus par Linux |