Monoprogrammation
|
Page préc.
Introduction |
Fin de page |
Page suiv.
Mémoire virtuelle |
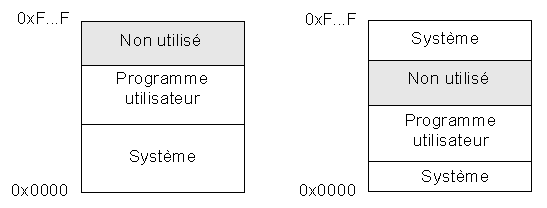
Monoprogrammation
Cette situation, générale dans le début des années 60, ne se rencontre plus que rarement, essentiellement dans le domaine de la "petite" micro-informatique (anciens ordinateurs du type Z-80, carte à microprocesseur, etc.). Son plus gros avantage est la simplicité des compilateurs, traducteurs et chargeurs correspondants. En effet, le programme est toujours chargé à la même adresse mémoire pour y être exécuté (adresse 0x100 dans le S.E. CP/M sur Z80). Lors de la compilation, toutes les adresses générées peuvent donc être absolues, c'est-à-dire correspondre exactement à l'implantation du programme à l'exécution.
Il est actuellement admis que le code des programmes est statique en cours d'exécution, c'est-à-dire ne peut être modifié dynamiquement au cours de son exécution. Il n'en a pas toujours été ainsi, en particulier sur les ordinateurs individuels. La possibilité que donnent les langages assembleurs de modifier des instructions, d'en créer de nouvelles, donc d'avoir un programme dont la taille croît pendant son exécution, entraîne la possibilité de provoquer de graves problèmes, volontaires ou non. En effet, si le programme vient se superposer partiellement au S.E., cela provoque inéluctablement une catastrophe la plupart du temps bien visible. L'utilisation de l'ordinateur par une seule personne à la fois limite les conséquences désastreuses d'un tel événement, qui n'en reste pas moins très gênant pour la victime. Généralement involontaire, cette violation de la mémoire interdite est parfois une technique utilisée de façon malfaisante, par exemple pour la propagation de "virus". Parfois plus perfide, l'effet d'une telle action peut être une modification imperceptible du comportement des fonctions du système.
Il est d'ailleurs (malheureusement !) facile d'obtenir un tel effet sur un ordinateur personnel, même en utilisant des langages de programmation de haut niveau (Pascal, C, ADA) en utilisant de façon incorrecte les pointeurs, en débordant la taille d'un vecteur, en utilisant des données dynamiques dont l'espace mémoire n'a jamais été alloué, etc.
Le débordement de la mémoire disponible peut aussi être obtenu (c'est une erreur fréquente) par la création de nouvelles données (mémoire dynamique) ou par des dépassements de pile (récursivité infinie ou trop importante).
Le problème de la protection doit donc être pris en compte, à la fois de façon matérielle et de façon logicielle - en utilisant au maximum les fonctions permettant de tester si les opérations voulues sont possibles (appel de la fonction MemAvail() avant l'opérateur new en Pascal Borland, test de la valeur de retour de l'opérateur new en C++ ou utilisation de la fonction
set_new_handler(),
test systématique des valeurs de retour des fonctions système sous UNIX, etc.)
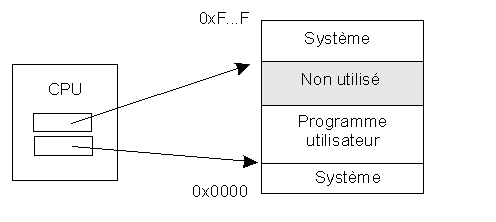
Il existe sur certains processeurs un ou deux registres appelés registres limites (figure suivante) pointant sur les adresses mémoire extrêmes utilisables par l'utilisateur.
A chaque accès mémoire d'un programme utilisateur par le processeur, celui-ci vérifie que l'adresse est à l'intérieur de ces valeurs limites.
Registres limites
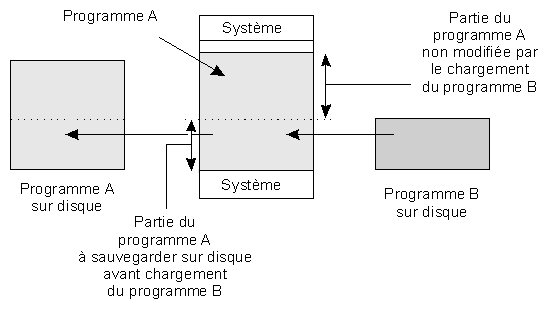
Lorsque la zone mémoire qui peut accueillir le programme est insuffisante, une solution assez simple à mettre en uvre est le recouvrement. Elle consiste à découper le programme (et les données statiques associées) en blocs de tailles différentes :

Schéma de recouvrement
En général, une partie du programme, appelée racine, est chargée une fois pour toutes dans la mémoire principale. Les autres blocs sont chargés à partir du disque au fur et à mesure des besoins. Chacun écrase le précédent et est lui-même écrasé par le suivant. Les seules limites sont :
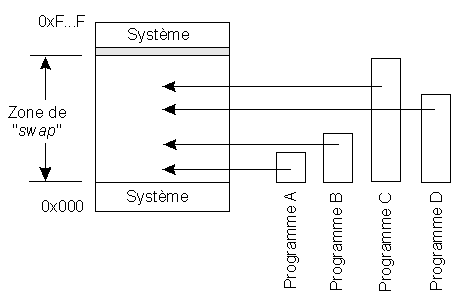
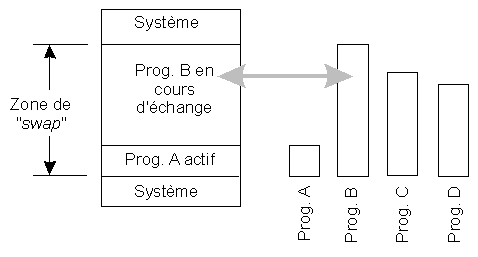
Va-et-vient
Compte tenu de la lenteur relative des accès disques, cette méthode est assez lourde et n'a pas été conservée dans sa forme la plus simple. Elle a été améliorée de plusieurs façons :
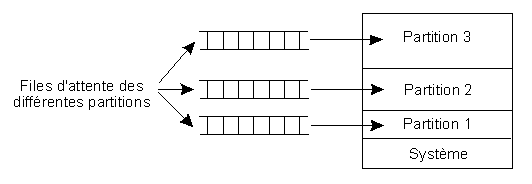
Partitions fixes avec files d'attente
Dans un contexte de multiprogrammation, elle consiste à diviser la mémoire en partitions de tailles prédéterminées (à la génération du système) et fixes (pas forcément égales). Dans son implémentation la plus simple, les programmes sont compilés en absolu, c'est-à-dire sont destinés à être exécutés dans une partition particulière. A chaque partition correspond une file d'attente des processus destinés à cette partition qui se remplit au fur et à mesure des lancements des programmes. Une fois son tour arrivé, le programme est chargé définitivement en mémoire où il demeurera jusqu'à la fin de son exécution.
Le premier inconvénient de cette méthode est la nécessité pour un processus d'être exécuté dans une partition particulière. On peut y remédier en utilisant un adressage relatif. Au moment du chargement du programme en mémoire, il est relogé par recalcul de toutes les adresses
Le deuxième inconvénient est l'impossibilité pour un processus dans une file d'attente d'en changer si une partition devient inutilisée :
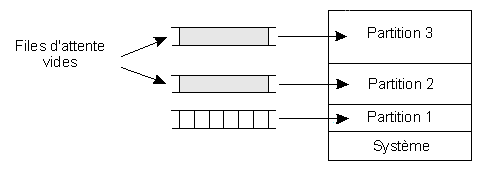
Cela peut conduire à une sous-utilisation de la mémoire centrale, certaines partitions étant saturées alors que d'autres sont inoccupées. Ce phénomène est très probable. En effet, lorsqu'un programme est lancé, il est logique de l'affecter à la partition de taille immédiatement supérieure à la sienne. On peut donc penser que les partitions de tailles extrêmes (les plus petites et les plus grandes) seront les moins souvent occupées. Cela a conduit à la technique des partitions fixes à une seule file d'attente.
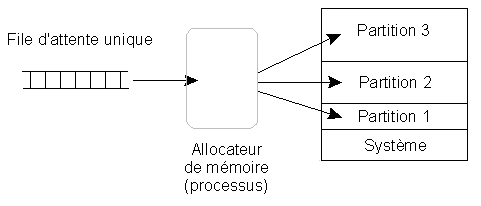
Partitions fixes à une seule file d'attente
Cependant, l'affectation à une partition est différée au dernier moment, lors du chargement du programme en mémoire. C'est l'allocateur de mémoire qui décide à quelle partition le programme est affecté, en fonction d'un algorithme d'affectation :
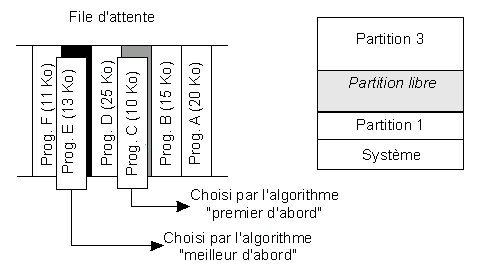
Affectation par allocateur mémoire
Le problème de la protection doit aussi être traité dans le cas de la multiprogrammation. Il est ici impossible d'associer deux registres limites pour chaque partition. Il suffit d'en avoir deux qui sont associés à la partition active. A chaque partition seront associées deux zones mémoire qui seront chargées dans les registres lorsque la partition est activée.
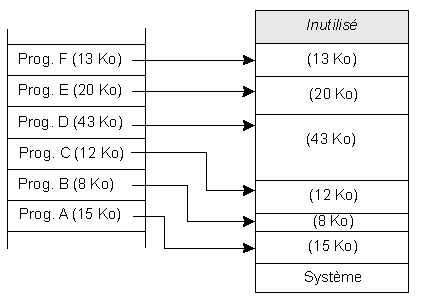
Allocation en mémoire contiguë
Puis un ou plusieurs programmes se terminent, libérant des zones mémoire qui peuvent ne pas être contiguës :
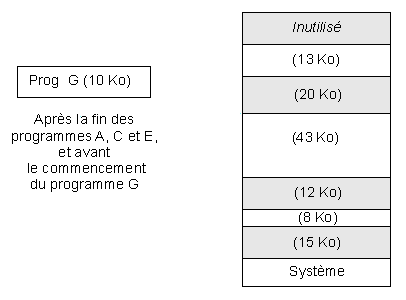
Les différentes solutions qui peuvent être adoptées pour gérer ces espaces mémoire libres sont présentées ci-après.
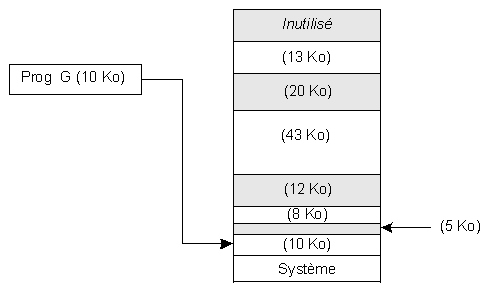
Algorithme dit "du premier espace libre suffisant"
Un inconvénient important de cet algorithme est de concentrer le placement en début de mémoire sans se soucier d'utiliser au mieux l'espace mémoire. C'est un algorithme rapide car la recherche est arrêtée dès qu'une solution est trouvée.
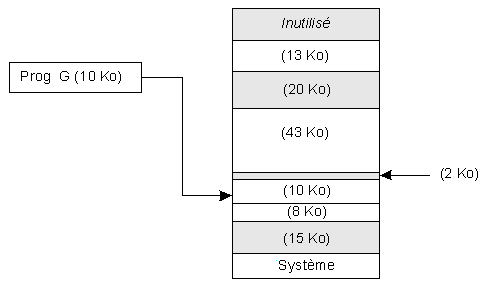
Cette méthode s'est aussi révélée moins efficace que celle du premier espace disponible. Knuth a montré que l'algorithme dit du "first fit" est souvent meilleur que celui du "best fit".

Algorithme "du plus mauvais espace libre"
Ainsi, après placement du programme, on espère que l'espace restant sera suffisant pour placer un nouveau programme. Là encore, il ne s'agit pas d'une très bonne idée.
Quel que soit l'algorithme retenu, il provoque l'apparition de trous (espaces mémoire inutilisés) qu'il faut bien gérer. Là aussi, plusieurs solutions ont été proposées.
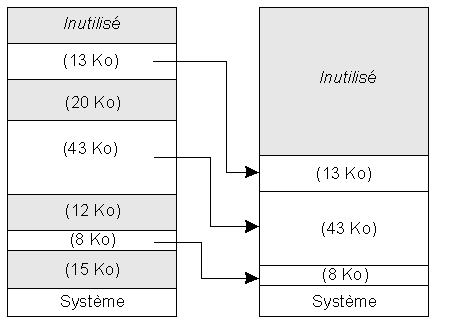
Compactage
Tous les trous disjoints sont alors réunis en un seul espace mémoire libre. Cette méthode offre pour unique avantage de ne pas chercher d'espace mémoire à chaque nouvelle allocation.
Au contraire elle présente plusieurs inconvénients importants. En premier lieu, le moment où le système lance une opération de compactage est totalement imprévisible. Cette opération prend un temps non négligeable et consomme les ressources du système, pénalisant fortement le travail en cours d'exécution à ce moment-là. Les effets dans un contexte "temps réel" sont catastrophiques. De plus, le compactage nécessite de reloger le programme. Si le mode d'adressage n'utilise pas un registre de base, il est nécessaire de conserver tout au long de l'exécution les tables de relogement (table des adresses présentes dans le programme). Enfin, cette méthode est incompatible avec une rotation rapide des programmes.
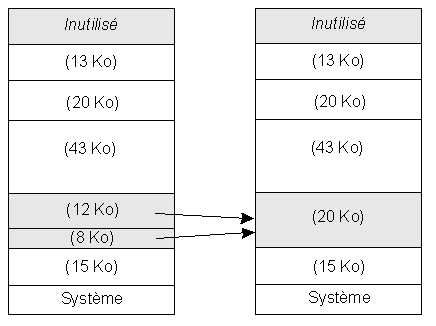
Coalescence des espaces libres
Cette coalescence peut être aisément obtenue si les trous sont conservés dans une liste triée par adresse mémoire. Il est ainsi facile de détecter qu'un trou dont on connaît l'adresse de début et le nombre d'unités d'allocation (par exemple l'octet), se termine à l'adresse voisine de l'adresse de début du trou suivant.
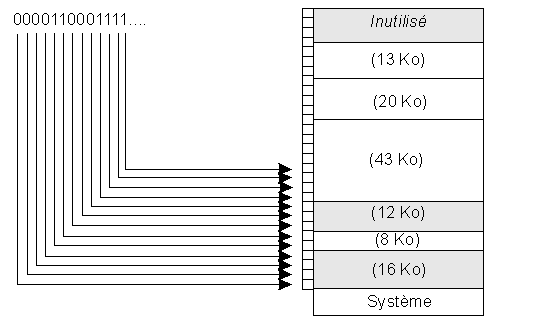
mapping de la mémoire
Un simple calcul montre que si 1 bit correspond à 4 octets, la table n'occupe qu'environ 3 % de la mémoire totale, ce qui est assez faible. Un avantage de cette méthode est de limiter la taille de la table à une valeur connue a priori (elle ne dépend que de la mémoire installée physiquement et de la valeur de n, et on peut donc savoir à quelle adresse elle sera implantée). Un inconvénient de cette méthode est la difficulté de trouver une suite de k bits à 0 si la taille mémoire recherchée est de k*n octets.

Espaces libres chaînés
Nous l'avons vu, cela permet d'appliquer l'algorithme du premier espace libre et la coalescences des trous.
L'algorithme du "meilleur espace mémoire libre" est évident : il suffit de parcourir la liste chaînée jusqu'à trouver un espace de taille suffisante.
L'algorithme "du premier espace libre" n'a plus aucun sens dans ce cas.
La recherche d'un espace est rapide, la coalescence des trous est très difficile et coûteuse en temps.
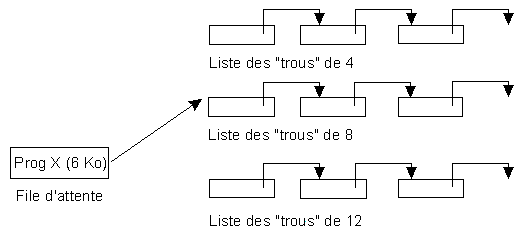
Plutôt que de créer une liste de pointeurs vers les trous, il est plus simple de chaîner directement les trous entre eux.
par exemple, il peut y avoir une chaîne de trous de moins de 4 Ko, une chaîne de trous de 4 à 8 Ko, une de chaîne de trous de 8 à 12 Ko, etc. La recherche d'un espace pour un programme de taille donnée est donc très rapide. La coalescence de trous, à plus forte raison appartenant à deux listes différentes, est encore plus complexe que précédemment.
Comme le montre la figure ci-dessous, la mémoire initiale de 1024 Ko constitue un seul bloc libre. Pour placer le programme A, le bloc de 1024 Ko est subdivisé en 1 bloc de 512 Ko, 1 bloc de 256 Ko, 1 bloc de 128 Ko, le dernier bloc de 128 Ko étant affecté au programme A. Le programme B nécessite un espace de 64 Ko qui n'existe pas. On choisit donc de partitionner un bloc de 128 Ko en deux blocs de 64 Ko, l'un étant affecté au programme B, l'autre étant libre. Le placement du programme C nécessite un bloc de 128 Ko obtenu en partitionnant un bloc de 256 Ko. La fin des programmes A puis B libère un bloc de 128 Ko, puis un autre de 64 Ko dont le "compagnon" est libre. Ils sont donc fusionnés en un bloc de 128 Ko dont le compagnon est lui aussi libre. Leur réunion conduit à un bloc de 256 Ko.

Suivant le même principe, on peut utiliser d'autres systèmes que le système binaire, par exemple la suite de Fibonacci définie par Si+1 = Si + Si-1, avec So = 1 et Si = 1, soit la suite 1, 1, 2, 3, 5, 8, 13, etc. Par exemple, un bloc de 13 Ko est partitionné en deux blocs, l'un de 8 Ko et l'autre de 5 Ko.
[1] La même technique est utilisée dans d'autres circonstances, par exemple pour décrire l'état d'occupation d'une zone disque (voir : Système de fichiers ext2).
|
Page préc.
Introduction |
Début de page |
Page suiv.
Mémoire virtuelle |