© D. Mathieu
mathieu@romarin.univ-aix.fr
I.U.T.d'Aix en Provence - Département Informatique
Créé le 13/01/2000 - Dernière mise à jour : 29/01/2001
![]()
Utilisation d'un vecteurAutres opérations sur les listes
Utilisation de la mémoire dynamique
GénéralitésAutres listes
Pile
Files
Listes doublement chaînées
Sentinelles
Listes circulaires
Listes multiples, listes de listes
Listes triées
| l = <e1, e2, ..., en> |
La notion d'ordre est fondamentale. Il ne s'agit pas d'un ordre sur les éléments eux-mêmes, c'est-à-dire sur leur valeur (par exemple un ordre alphabétique), mais sur les rangs de ces éléments. Par exemple on peut considérer une liste de processus à lancer sur une machine, ordonnée suivant les priorités décroissantes de ces applications, une liste de fenêtres à afficher à l'écran de la plus éloignée vers la plus proche de l'utilisateur (ordonnée selon l'axe z : Z-Order).
Soit
Il existe k >= 0
tel que p = succk (tete (l)),
Si n = 0, alors
l est appelée une liste vide,
Si n = 0, alors
tete
(l) est indéfini,
succn (tete (l)) est indéfini.
Primitives de base
Notons de façon formelle CListe le type d'une liste d'éléments de type CElement. Les types des listes et des éléments peuvent être des classes, des pointeurs ou des références, génériques ou pas, etc...
Accès à la tête : tete(l).La première primitive fondamentale est :
| CElement CListe::GetTete (void) const; |
La fonction membre GetTete() de la classe
CListe
permet d'accéder au premier élément de la liste. Les
spécifications formelles indiquées plus haut précisent
que la tête n'est définie que si la liste n'est pas vide.
La liste doit donc offrir l'une des deux fonctions membres suivantes :
| bool CListe::EstVide (void) const; |
ou
| unsigned int CListe::GetNbreElements (void) const; |
Remarques :
| bool CListe::EstVide (void) const { return !GetNbreElements (); } |
| if (!Liste.EstVide())
{ CElement Courant = Liste.GetTete(); // suite du traitement } |
Accès à l'élément suivant : succ(p,l)De nombreuses possibilités peuvent être envisagées, réalistes ou non. On peut par exemple considérer que c'est une fonctionnalité de la liste. En effet le successeur d'un élément n'a de sens que dans une liste donnée. Une première solution pourrait être :
| CElement CListe::GetSuivant (CElement p); |
Cela signifie clairement :
| CElement CElement::GetSuivant (void); |
Quoiqu'évidente, cette solution est quand même ambiguë car le suivant d'un élément n'a de sens qu'au sein d'une liste, qui semble disparaître ici, au moins explicitement.
La dernière spécification de la liste
est plus difficile à mettre en uvre : elle précise qu'un
élément n'a un successeur que s'il n'est pas le dernier.
Il faut donc pouvoir tester si un élément est le dernier
de la liste :
| bool CListe::EstDernier (CElement p) const; |
ce qui permettrait d'écrire :
| if (!Liste.EstVide())
{ for (CElement Courant = Liste.GetTete(); ; Courant = Liste.GetSuivant (Courant)) { // traitement de l'élément courant if (Liste.EstDernier
(Courant)) break;
|
Avec l'autre solution :
| bool CElement::EstDernier (void) const; |
et :
| if (!Liste.EstVide())
{ for (CElement Courant = Liste.GetTete(); ; Courant = Courant.GetSuivant()) { // traitement de l'élément courant if (Courant.EstDernier
()) break;
|
Une alternative est possible si le rang d'un élément
dans la liste est (ou peut être) connu. Par exemple :
| unsigned int CListe::GetRang (CElement p) const; |
permettrait d'écrire :
| if (!Liste.EstVide())
{ for (CElement Courant = Liste.GetTete(); ; Courant = Courant.GetSuivant()) { // traitement de l'élément courant if (Liste.GetRang (Courant)
= Liste.GetNbreElements()) break;
|
Autres primitivesDe nombreuses autres primitives peuvent être implémentées à partir des deux premières, afin de faciliter l'utilisation de la liste. Ainsi :
succk(p,l)
| CElement CListe::GetSuivantK (CElement p, unsigned int k) const
{ CElement Courant = p; for (int i = 1, i <= k; ++i) Courant = GetSuivant (Courant); return Courant; } // GetSuivantK () |
fonction à laquelle il faudrait ajouter toutes les validations nécessaires.
Accès par le rang :
| CElement CListe::GetElement (unsigned int Rang) const
{ CElement Courant = GetTete(); for (int i = 1, i < Rang; ++i) p = GetSuivant (Courant); return Courant; } // GetElement () |
| GestProcess(10), GestMem(7), GestDisk(6), CalcReact(3), Print(1) |
classés par priorité décroissante (entre parenthèses)
et dont les identificateurs sont explicites. Les trois premiers, processus
du système d'exploitation, ont de fortes priorités. Le dernier,
Print
est une impression en tâche de fond de très faible priorité.
CalcReact est un processus utilisateur. Nous utiliserons la classe
CProcess
suivante :
| class CProcess
{ CTask m_Task; CPriorite m_Priorite; // ... }; // CProcess |
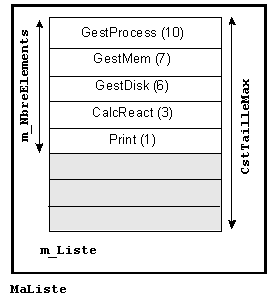
| class CListe
{ CProcess m_Liste [CstTailleMax]; // CstTailleMax supposé défini unsigned m_NbreElements; public :
CProcess GetTete
(void) const { return m_Liste [0]; }
}; // CListe |
La construction, la destruction et le remplissage ne sont pas développés.
La liste est dite propriétaire car elle inclut les éléments qu'elle ordonne : si la liste est détruite, les éléments disparaissent.
Dans cette implémentation, le mécanisme
de passage à l'élément suivant est évident,
il suffit d'incrémenter d'une unité le rang physique (l'indice)
de l'élément. Cela nécessite une fonction, que l'utilisateur
n'a pas à connaître (fait seulement partie de l'implémentation),
et qui suppose l'existence de l'opérateur == de comparaison
de deux CProcess :
| unsigned int CListe::GetIndice (const CProcess & Process) const
{ int i = 0; for (; i < m_NbreElements && Process != m_Liste [i]; ++i); return i; } // GetIndice() |
Remarques :
| CProcess CListe::GetSuivant (const CProcess & Process) const
{ return m_Liste [GetIndice (Process) + 1]; } // GetSuivant () CProcess CListe::GetProcess (unsigned int Rang) const
} // GetProcess () |
Dans la pratique, une telle implémentation serait sans doute trop coûteuse, car elle nécessite de toujours recommencer la recherche à partir du début, ce qui est la définition même d'une liste, seulement accessible par son premier élément. La mise à jour de la liste (par exemple, le passage en urgence de CalcReact : priorité 10), nécessite des opérations d'autant plus coûteuses que la taille les éléments de la liste est importante et que le nombre d'éléments est grand. L'ajout d'un élément (par exemple GestModem de priorité 5) ou une suppression (de CalcReact par exemple) sont aussi des opérations coûteuses car elles entraînent le décalage de N/2 éléments en moyenne (en l'absence de toute autre astuce). Une solution consiste à utiliser une liste non propriétaire :
2) - Une façon simple de limiter les transferts d'information liés à la maintenance de la liste est d'utiliser un vecteur de pointeurs vers des éléments, comme l'illustre la figure 3.
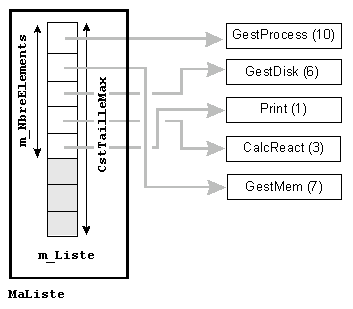
3) - Si les ordres physique et logique ne coïncident pas, il faut alors que chaque élément conserve l'indice de son suivant, ce qui peut être réalisé par la liste MaListe, comme le montre la figure 4.
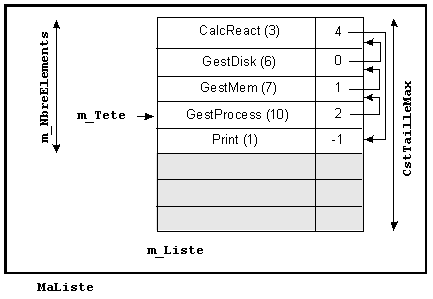
Le premier élément de la liste n'étant pas le premier élément du tableau, il est nécessaire d'ajouter son indice comme donnée membre de la classe CListe, d'identificateur m_Tete.
L'implémentation nécessite la construction d'une classe supplémentaire, CElement, comme le montre la figure 5.
| class CElement
{ public : int m_Suivant; CProcess m_Process; }; // CElement class CListe
int GetIndice (const CProcess & Process) const; public :
unsigned GetNbreElements (void) const { return
m_NbreElements; }
CProcess GetTete (void)
const;
}; // CListe |
Les fonctions GetNbreElements() et EstVide()
sont inchangées. En revanche, l'accès aux différents
éléments de la liste est plus complexe (figure 6) :
| CProcess CListe::GetTete (void) const
{ return m_Liste [m_Tete].m_Process; } // GetTete() int CListe::GetIndice (const CProcess & Process) const
} // GetIndice() CProcess CListe::GetSuivant (const CProcess & Process) const
} // GetSuivant() CProcess CListe::GetProcess (unsigned int Rang) const
for (i = m_Tete, j = 0; j < Rang; i = m_Liste
[i].m_Suivant, ++j);
} // GetProcess() |
Comme on le voit, l'accès est moins simple. Cependant la mise à jour de la liste (le passage en urgence de CalcReact : priorité 10), puis l'ajout d'un élément (le processus GestModem de priorité 5) ne nécessitent que des modifications mineures (figure 7).
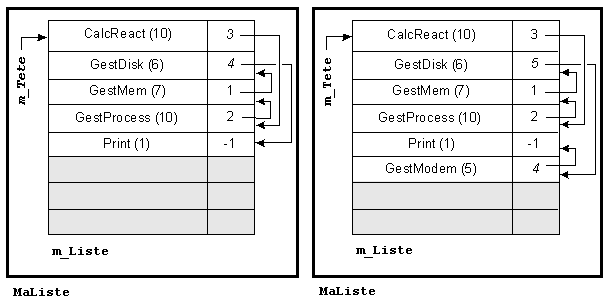
L'inconvénient principal de l'utilisation d'un vecteur est la nécessité de fixer une fois pour toutes une taille maximale de la liste. La solution dynamique est donc parfois préférable.

Les déclarations correspondantes sont les
suivantes (figure 9) :
| class CElement
{ public : CProcess m_Process; CElement * m_Suivant; }; // CElement class CListe
public :
unsigned GetNbreElements (void) const { return
m_NbreElements; }
CProcess GetTete (void)
const;
}; // CListe |
La fonction membre GetIndice() est ici remplacée
par GetElement() qui renvoie un pointeur vers l'élément
correspondant au processus recherché. Les primitives de base peuvent
être implémentées ainsi (figure 10) :
| CProcess CListe::GetTete (void) const
{ return m_Tete->m_Process; } // GetTete() CElement * CListe::GetElement (const CProcess & Process) const
} // GetElement() CProcess CListe::GetSuivant (const CProcess & Process) const
} // GetSuivant () CProcess CListe::GetProcess (unsigned int Rang) const
return pElem->m_Process; } // GetProcess() |
Cette représentation possède toutes les propriétés désirées:
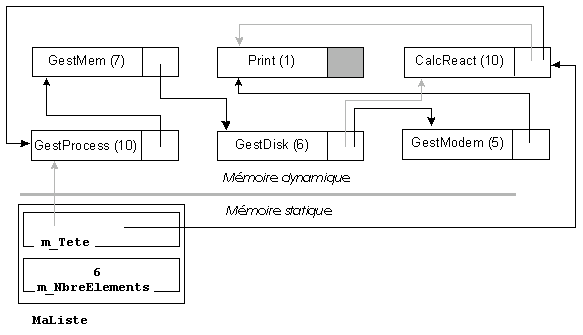
La figure 12 illustre la suppression de GestMem. Comme précédemment, les flèches grises montrent les chaînages avant suppression. Il faut remarquer que, pour supprimer logiquement le processus GestMem de la liste, il suffit de modifier le chaînage de l'élément qui le précède, mais pas son propre chaînage vers le suivant. Bien entendu, cet élément peut devenir inaccessible et ce problème sera traité en travaux dirigés.
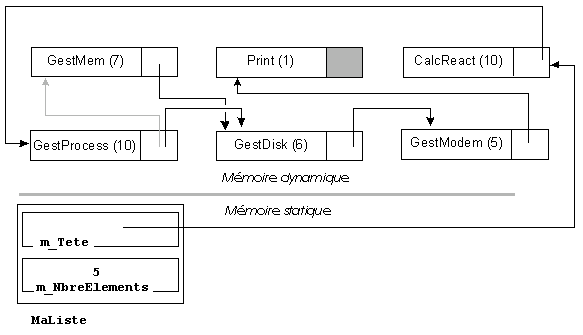
Le pointeur m_Suivant du dernier élément ne pointe sur aucun élément. Sa valeur est conventionnellement 0 : en C/C++, un pointeur nul correspond à une adresse invalide.
La création d'un nouvel élément doit se dérouler en cinq étapes :
2) - Comme précédemment, il peut être avantageux d'utiliser une liste non propriétaire de l'information, dans laquelle chaque élément pointe à la fois sur l'information (ici le processus) et l'élément suivant, comme l'illustre la figure 13.
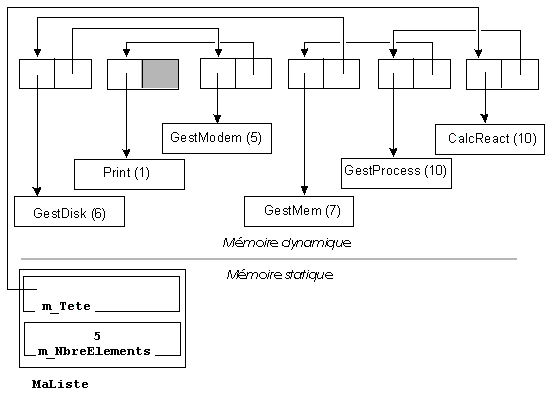
L'implémentation en est légèrement
modifiée :
| class CElement
{ public : CProcess * m_Process; CElement * m_Suivant; }; // CElement class CListe
public :
unsigned GetNbreElements (void) const { return
m_NbreElements; }
CProcess GetTete
(void)
const;
}; // CListe |
| CProcess CListe::GetTete (void) const
{ return *(m_Tete->m_Process); } // GetTete() CElement * CListe::GetElement (const CProcess & Process) const
} // GetElement() CProcess CListe::GetSuivant (const CProcess & Process) const
} // GetSuivant() CProcess CListe::GetProcess (unsigned int Rang) const
return *(pElem->m_Process); } // GetProcess() |
| CProcess * CListe::GetSuivant (const CProcess & Process) const; |
La solution non propriétaire remédie à cet inconvénient, mais en apporte un autre : l'utilisateur, récupérant un pointeur sur l'information, peut l'altérer ou même la détruire directement sans passer par la liste.
Pour rendre le code utilisable, il est nécessaire de le sécuriser : chaque opération doit être analysée et les causes potentielles d'erreurs testées. Comme toujours, deux attitudes peuvent être choisies :
Les deux méthodes ont des avantages et des inconvénients, le principal en ce qui concerne les exceptions étant de ralentir l'exécution, mais son avantage étant une très grande lisibilité. Le principal inconvénient de l'autre méthode est de pousser l'utilisateur à supprimer les tests pour rendre le code plus lisible ... En tout état de cause, il est préférable de ne pas mélanger les deux techniques, si possible !
A l'intérieur de ces classes de structures de données existe une grande variété. Par exemple, les listes linéaires peuvent être simples, doubles, circulaires, les arbres peuvent être binaires, n-aires, parfaits, etc...
Pour être programmées, ces différentes structures de données doivent utiliser les possibilités d'un langage de programmation. Une même structure peut utiliser des tableaux (array), de la mémoire dynamique ou autres. Un tableau peut aussi bien servir à implémenter une liste circulaire, un arbre binaire, un graphe, etc...
Un conteneur est un objet destiné à stocker et à restituer des informations, selon des règles particulières. Les conteneurs les plus simples sont les files et les piles. La façon dont un conteneur organise les informations qu'il stocke fait partie de l'implémentation et peut (doit ?) être cachée à l'utilisateur. Une pile peut être implémentée par une liste simple, elle-même implémentée par un tableau ou des éléments dynamiques chaînés. Certains conteneurs peuvent même faire intervenir simultanément plusieurs structures de données : un conteneur "arbre généalogique" est naturellement implémenté par une structure arborescente, mais l'ensemble des frères et surs (fratrie) correspond très bien à une liste circulaire.
| EstVide()
Empile () Depile () Sommet () |
inchangé
remplace InsereEnTete() remplace SupprimeEnTete() remplace GetInfo (/* Rang = */ 0) |
| EstVide()
Depose () Retire () |
inchangé
remplace InsereEnQueue() remplace SupprimeEnTete() |
| class CElement
{ public : CProcess * m_Process; CElement * m_Suivant; CElement * m_Precedent; }; // CElement |
| class CListe
{ unsigned int m_NbreElements; CElement * m_Tete; CElement * m_Queue; // ... }; // CListe |
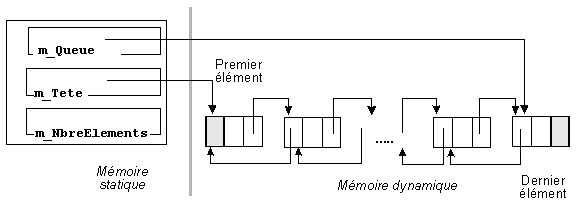
L'algorithme de suppression présente aussi la même complexité. De plus, les cas particuliers qui doivent être envisagés sont relativement rares : si le rang de l'insertion est équiprobable, il y a une chance sur N (nombre d'éléments) qu'elle se fasse en tête par exemple.
Une technique souvent utilisée consiste à unifier tous les cas, c'est-à-dire à forcer toute insertion ou suppression à être effectuée en milieu de liste. Elle nécessite d'ajouter à la liste deux éléments, appelés sentinelles, qui ont pour seul rôle de borner la liste. Ils sont physiquement présents, mais ne sont pas comptabilisés et ne contiennent pas d'information. Ils doivent être créés et chaînés entre eux dès la création de la liste (figure 17) et détruits lorsque la liste est détruite.
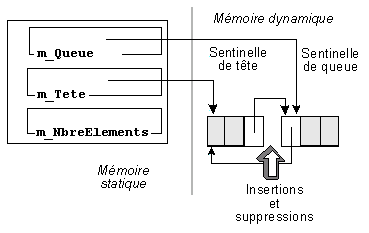
Tout au long de la vie de la liste, m_Tete pointe sur la première sentinelle, et m_Queue sur la seconde. Toutes les insertions et suppressions sont effectuées entre ces deux sentinelles (figure 18).
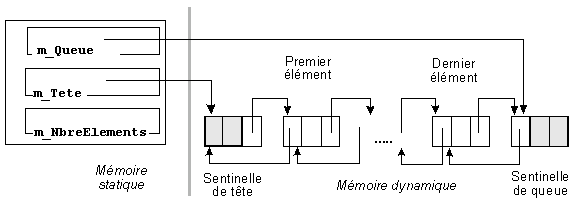
Les modifications entraînées sont minimes.
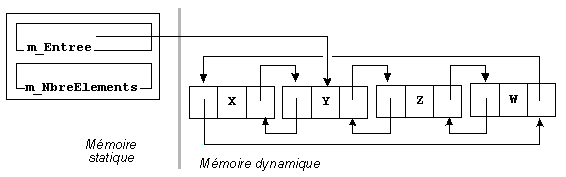
La présence de sentinelle(s) compliquerait le parcours de la liste, mais son absence nécessite de traiter séparément le cas de l'insertion dans une liste vide et de la suppression d'une liste limitée à un seul élément.
Les listes circulaires sont très souvent utilisées dans les systèmes d'exploitation, par exemple pour établir un "tour de rôle" dans les processus qui se partagent l'accès au processeur (voir cours de Systèmes d'exploitation, 2ème année, chapitre "gestion des processus", technique de "round robin")
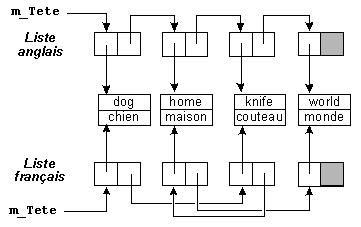
D'autres structures complexes seront étudiées en travaux dirigés.
Dans la première l'ordre est intrinsèque à la liste, c'est un invariant : la liste est toujours triée. Dès lors, cet ordre doit être respecté pendant toute la durée de vie de la structure. En particulier toutes les opérations qui font évoluer la liste (en particulier l'ajout) doivent maintenir cet ordre : les opérations essentielles sont la recherche, l'insertion ou la suppression d'un élément de clé donnée, l'utilisateur n'ayant pas en général à se préoccuper du rang auquel ces opérations sont effectuées. Pour maintenir l'ordre de la liste, l'utilisateur ne peut insérer une information à un rang donné. Une liste non propriétaire peut difficilement garantir qu'elle est ordonnée.
L'approche de la bibliothèque standard du C++ (Standard Template Library ou STL) qui sera étudiée ultérieurement, est totalement différente : le tri est effectué par un algorithme, générique, qui peut être appliqué à différentes sortes de structures. L'ordre n'est pas une propriété intrinsèque de la liste, mais une propriété vérifiée à un instant donné. L'inconvénient majeur est d'obliger l'utilisateur à trier la liste chaque fois qu'il veut profiter de cette propriété si la liste a subi des transformations inconnues depuis son précédent tri. L'avantage est de permettre de trier la liste plusieurs fois dans la même application, selon plusieurs critères de tri différents.
![]()
© D. Mathieu
mathieu@romarin.univ-aix.fr
I.U.T.d'Aix en Provence - Département Informatique