Page prec.
Fin page
Page suiv.
Architectures générales des serveurs
L'architecture d'un serveur dépend de nombreux paramètres qui sont eux-mêmes fonction de la nature du ou des services qu'il doit rendre : service unique ou multiple, constitué d'une ou de plusieurs requêtes, volume de données transmettre réduit ou important, etc.
Les contraintes que doit respecter un serveur sont :
-
être équitable vis-à-vis de tous les clients,
-
donner l'illusion de servir chaque client comme s'il était seul (parallélisme ou pseudo-parallélisme, en servant de façon préférentielle ceux qui ne consomment que peu de temps du serveur),
-
minimiser la charge du système d'exploitation qui l'héberge, tant en ce qui concerne le temps utilisé que le nombre de ressources du système immobilisées par le serveur : descripteurs, nombre de ports disponibles, nombre de processus concurrents, etc.
Plusieurs schémas différents peuvent être envisagés.
Un serveur itératif est un serveur qui traite les requêtes l'une après l'autre.
Un serveur concurrent est au contraire un serveur qui traite plusieurs requêtes simultanément.
En général un serveur itératif n'est suffisant que pour des applications très simples.
Le temps de réponse du serveur à une requête est le temps mis par le serveur pour extraire, une requête, la traiter et renvoyer au client la réponse.
Le temps de réponse observé par un client est le temps qui s'écoule entre l'émission d'une requête et la réception de la réponse du serveur.
Lorsque le serveur est itératif, chaque requête est placée en file d'attente et traitée séquentiellement.
Le temps de réponse observé par le client est d'autant plus long que la file d'attente est longue.
La solution itérative ne peut être choisie que si le temps d'attente d'un client est inférieur à une valeur fixée, pour une file d'attente de taille moyenne.
Elle est en général mise en uvre avec un protocole d'accès non connecté qui se prête plus facilement à l'implémentation.
Un serveur concurrent est nécessaire dans les cas suivants :
-
l'élaboration de la réponse nécessite des E/S qui ralentissent le traitement,
-
le temps de traitement d'une requête peut énormément varier d'une requête à l'autre,
-
le serveur tourne sur une machine multiprocesseurs.
Serveur itératif non connecté
Après avoir créé la socket (socket()) et l'avoir liée à un port défini (bind()), le serveur attend un datagramme sur la socket, élabore la réponse et la renvoie au client dont il a reçu l'adresse en même temps que le datagramme, puis retourne lire une nouvelle requête.
Il traite les requêtes l'une après l'autre mais sert en pseudo-parallélisme différents clients
Serveur itératif connecté
Après avoir créé la socket (socket()) et l'avoir liée à un port défini (bind()), le serveur attend une demande de connexion au moyen de l'appel à la fonction accept().
Lorsqu'il l'a reçu, il échange avec le client, attendant toutes ses requêtes et lui envoyant les réponses.
Lorsque le client a terminé, le serveur ferme la socket de communication et se remet en attente de connexion par accept().
Serveur concurrent non connecté
Lorsque le serveur reçoit une requête, il crée un processus fils (un esclave), lui communique l'adresse du client, la socket par laquelle l'esclave doit envoyer la réponse et retourne en attente d'une nouvelle requête.
L'esclave pour sa part prépare la réponse, la renvoie et se termine.
La création d'un nouveau processus pour répondre à une requête est en général une opération lourde, longue et consommatrice de ressources du système.
Cette architecture doit donc être réservée à des cas très particuliers où le service se réduit à seule requête dont le traitement peut être très long par rapport à la création d'un esclave.
Serveur concurrent connecté
Comme dans le cas précédent, chaque fois que le serveur reçoit une demande de connexion (par la fonction accept()), il crée un processus esclave (par appel à la fonction système fork()) auquel il transmet le socket descriptor de la socket de communication puis retourne attendre une nouvelle demande de connexion.
Le processus esclave pour sa part peut entamer un échange avec le client puisque la communication est établie de bout en bout entre ces deux processus.
Aucun autre ne peut interférer.
La figure suivante illustre cette architecture.
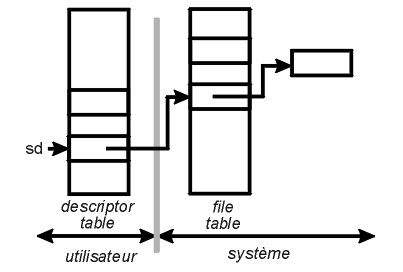
 L'état de la table des descripteurs après exécution de la fonction système socket() est le suivant :
L'état de la table des descripteurs après exécution de la fonction système socket() est le suivant :
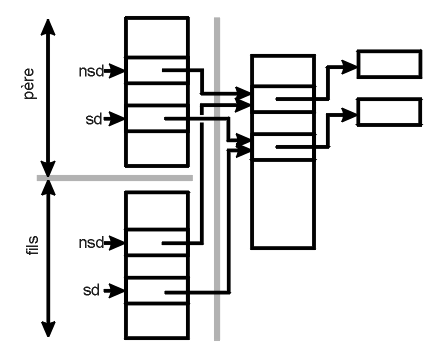
La figure suivante illustre l'état de la table des descripteurs après exécution de la fonction système accept().

La figure suivante illustre l'état de la table des descripteurs après exécution de la fonction système
fork().
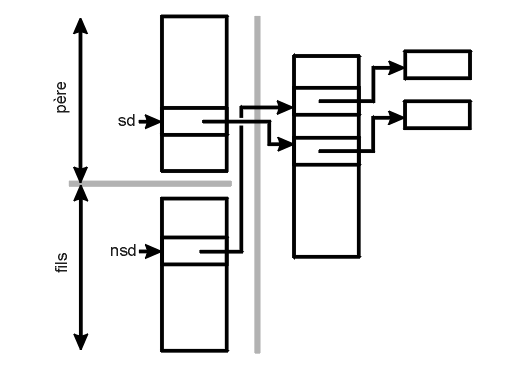
 L'état de la table des descripteurs après mise en place complète du processus esclave et fermeture des descripteurs inutiles est le suivant :
L'état de la table des descripteurs après mise en place complète du processus esclave et fermeture des descripteurs inutiles est le suivant :
Il y a deux possibilités lors de la création du processus esclave :
-
le code de ce processus est réduit, et il peut être inclus dans le code du serveur,
-
le code est volumineux, ou très spécifique, ou sujet à des modifications, et il doit être dans une commande indépendante qui est lancée par la fonction système exec..().
Une dernière possibilité est offerte si le serveur est écrit dans un langage permettant le multitâche (ADA par exemple) ou si le système autorise l'utilisation de threads.
Cette structure de serveur n'est justifiée que si l'on veut profiter des possibilités de temps partagé qu'offre le système UNIX : si un service est très long, le processus esclave épuisera son quantum de temps et le système le pénalisera.
Serveur concurrent connecté mono-processus
Le serveur concurrent connecté multi-processus présenté ci-dessus présente plusieurs inconvénients majeurs : en premier lieu celui de surcharger le système d'exploitation et de consommer des ressources en nombre limité (le nombre de processus).
En second lieu le passage d'un processus à l'autre se fait par commutation de contexte qui prend du temps.
Si le traitement d'une requête ne fait pas appel à des E/S et s'il est assez court pour pouvoir être terminé pendant un quantum de temps, il est préférable de se limiter à un seul processus serveur et d'utiliser la fonction système select(), déjà étudiée avec les autres fonctions système consacrées aux fichiers.
Grâce à cette fonction il est possible de mettre en place une attente généralisée sur plusieurs événements : lecture, écriture, exception (OOB), ou donner un délai d'attente maximal.
Le serveur peut offrir une socket de connexion, puis gérer simultanément plusieurs sockets de communication avec des clients différents.
Il se présente sous la forme d'une boucle (infinie) qui attend, au moyen de la fonction système select(), un événement sur toutes les sockets, de connexion et/ou de communication.
La sortie de cette fonction bloquante indique qu'au moins un événement est arrivé sur une des sockets.
Les masques sont analysés et les événements sont traités, après quoi le serveur retourne à l'appel de la fonction select().
Serveur multi-protocoles
De nombreux services standard sont offerts en mode connecté (TCP) ou non connecté (UDP).
Afin d'éviter la multiplication des processus, dont la partie "service" serait identique, il est préférable de n'en faire qu'un seul qui offre les deux protocoles : une socket de connexion pour le protocole TCP et une socket UDP pour recevoir les datagrammes de demande de service.
De nouveau on utilise la fonction select() qui permet d'attendre à la fois sur ces deux sockets et sur toutes les sockets de communication créées par les appels de la fonction accept().
Serveur multi-services
Un serveur peut offrir plusieurs services simultanément.
Il s'agit d'une généralisation du serveur ci-dessus : plusieurs sockets, liées à différents numéros de port, sont créées pour les différents services.
Page prec.
Début page
Page suiv.